【簡単3分】AWS EC2 (Amazon Linux 2)でFIWARE環境を作成してみよう

こんにちわ。新卒が入ってきて自分の存在意義を考え始めた2年目のゆきとです。
最近、IoTを活用したスマートシティ検討がより活発化していく流れの中で、一際注目を浴びているサービスがFIWARE(分野横断的なデータ流通に主眼を置いたデータ管理基盤)です。
今日は、そんなFIWAREをEC2で使うための環境設定方法を紹介していきます。
*「はじめに」ではFIWAREの紹介をしているだけですので、環境構築だけしたいという方は、「はじめに」を飛ばしてください。
はじめに
FIWAREとは
FIWAREとは分野横断的なデータ流通に主眼を置いたデータ管理基盤です。
7カテゴリー、約40種のモジュール群で構成され、用途に合わせて自由に組み合わせて利用できます。
各モジュールは、OMA(Open Mobile Alliance)で標準化された「NGSI(Next Generation Service Interface)」で規定されており、これを通してデータの受け渡しが行われます。
要は、FIWAREは柔軟性の高いデータモデルで統合管理を可能にするすごいやつなんです。

モジュール群の7カテゴリーは以下の通り。
- DATA/CONTEXT:コンテキスト管理、データ・メディア統合
- Internet of Things:IoTデバイスのサポート
- Advanced UI:3DやAR機能付きWeb UI等
- Security:セキュリティ・モニタリング認証、アクセス管理
- Interface to Networks and Devices (I2ND):ネットワーク、ロボット制御等
- APPS:可視化、ダッシュボード、データセット/サービスの公開
- Cloud:クラウド環境

FIWAREのメリット
メリット1
FIWAREの1番の売りは、なんといっても「低コストかつ効率的な基盤開発が可能」であるということでしょう。
モジュールはいずれもOpenStackやHadoop、ckanなど、新旧を含めたOSSをベースに開発されており、そのリファレンス実装は「FIWARE Catalogue」としてWebで広く公開されています。あとは雛形を参考に、必要なモジュールを組み合わせたり、機能を独自に追加したりなどの作業で、ライセンス費用の負担なくシステム環境を整備できたりもします。(すげー...)
メリット2
FIWAREならではのデータ管理性の高さも外せないポイントです。
その秘密は実世界の多様な情報を抽象化して表現可能な独自のデータモデルにあり、たとえば温度センサーであれば、その属性である『温度』と、属性値である『摂氏』『20』『設置場所』など、多様なデータを『コンテキストデータ』として格納できる点にあります。また、ネットワーク経由でのデータ検出/取り込みのためのAPIも用意されています。
メリット3
システムの独立性の高さも事業者、開発者にとっては外せないポイントです。
FIWAREは、アプリケーションとデータがNGSIにより、いわば“疎結合”となることで、システム改修の手間とコストを軽減しています。結果、システムの見直しや新サービスの追加も容易となり、成功したプロジェクトのデータモデルを参考に、取り組みの横展開までも容易にしてしまいます。
すでに「環境」「交通」「廃棄物管理」「天候」などの領域でいくつものデータモデルが公開されています。

ここまで読むと、FIWAREがなんたるかがわかってきたのではないでしょうか?
さて、前置きが長くなってしまいましたが、それでは本題のFIWAREをEC2で使うための環境設定方法を紹介していきます。
FIWAREをEC2で使うための環境設定方法
開発環境
- windowsPC
環境設定方法詳細
FIWAREをEC2で使うための環境設定方法の手順は下記のステップです。
1. 特定の条件でEC2インスタンスを作成する
下記の条件を満たす形でEC2を作成します
- リージョン : 東京(ap-northeast-1)
- OS : Amazon Linux 2 AMI (HVM), SSD Volume Type
- インスタンスタイプ : t2.micro
- セキュリティグループ : allow-ssh (22番ポートを開放していれば名前はなんでもよい)
2. Teratermを使ってEC2へログイン
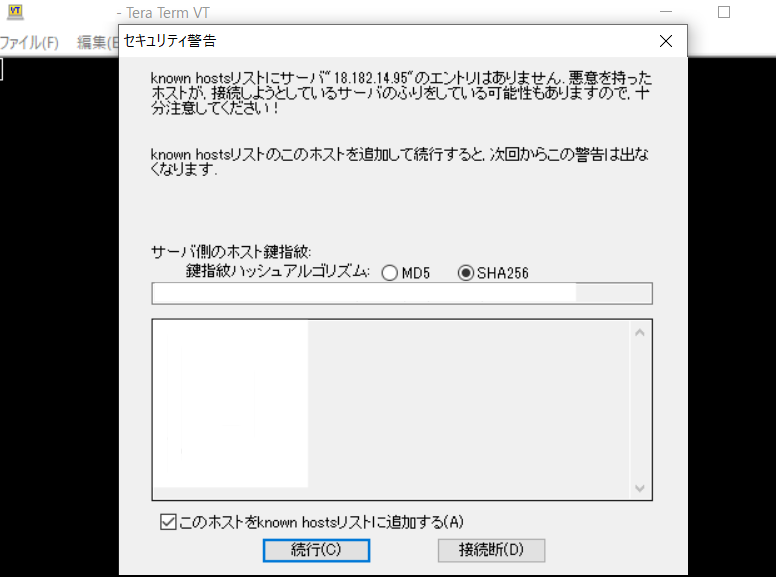
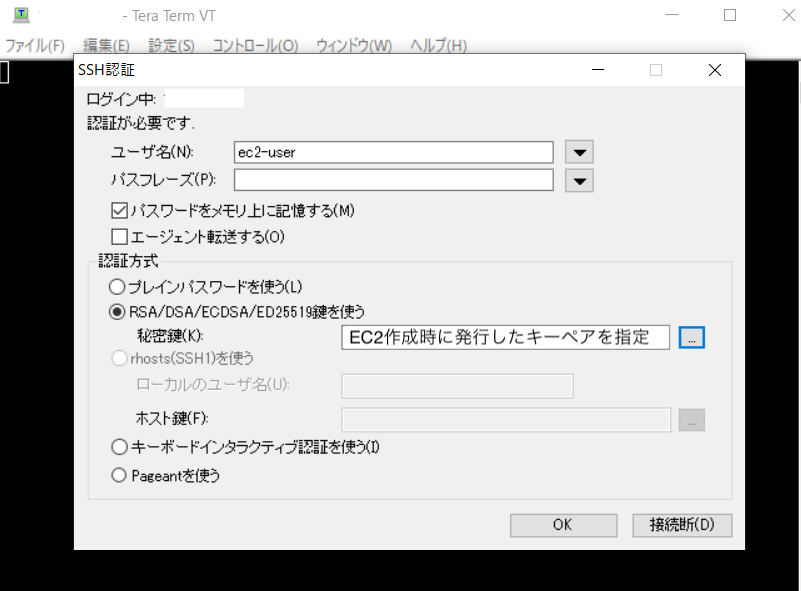
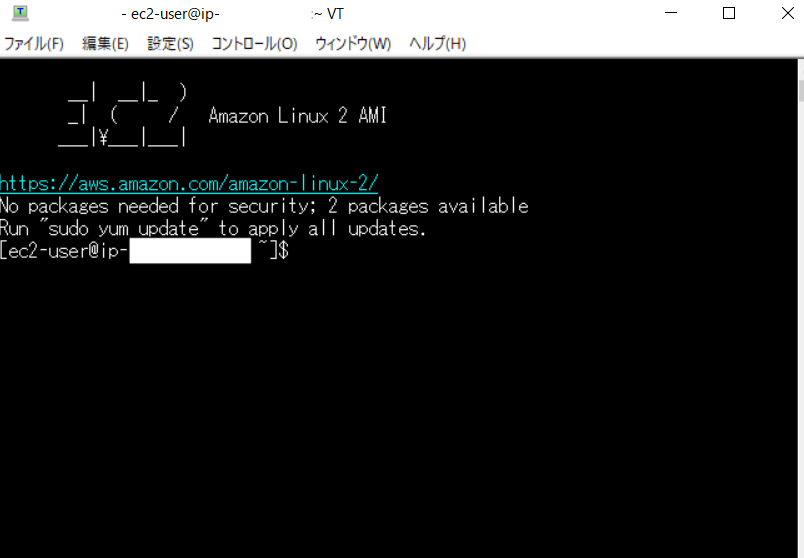
Teraterm(windowsに内蔵された基本ツール)を使って、ステップ1で作成したEC2へ接続します。
Teratermを使って、EC2へログインをする際に必要な設定項目は下記です。
* 下の写真を追いかけながら、EC2へのログインを試みてください。

3. EC2の中にdocker、docker-composeをインストールする
-
Dockerのインストール(2021年4月9日現在Docker 19.03.13-ceがインストールされます)
-
sudo yum install -y docker
-
sudo systemctl start docker
-
sudo usermod -a -G docker ec2-user(※ec2-userの場合を想定)
-
-
(オプション)自動起動を有効にする
-
sudo systemctl enable docker
-
-
docker-composeのインストール
-
sudo curl -L https://github.com/docker/compose/releases/download/1.28.5/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose (Docker Composeは1.28.5をインストールします)
-
sudo chmod +x /usr/local/bin/docker-compose
-
-
一度EC2からログアウト、再ログイン(docker、docker-composeコマンドが使えるようになっています)
4. docker環境にFIWAREを導入する
- docker環境にFIWAREを導入
- docker pull mongo:3.6
- docker pull fiware/orion
- docker network create fiware_default
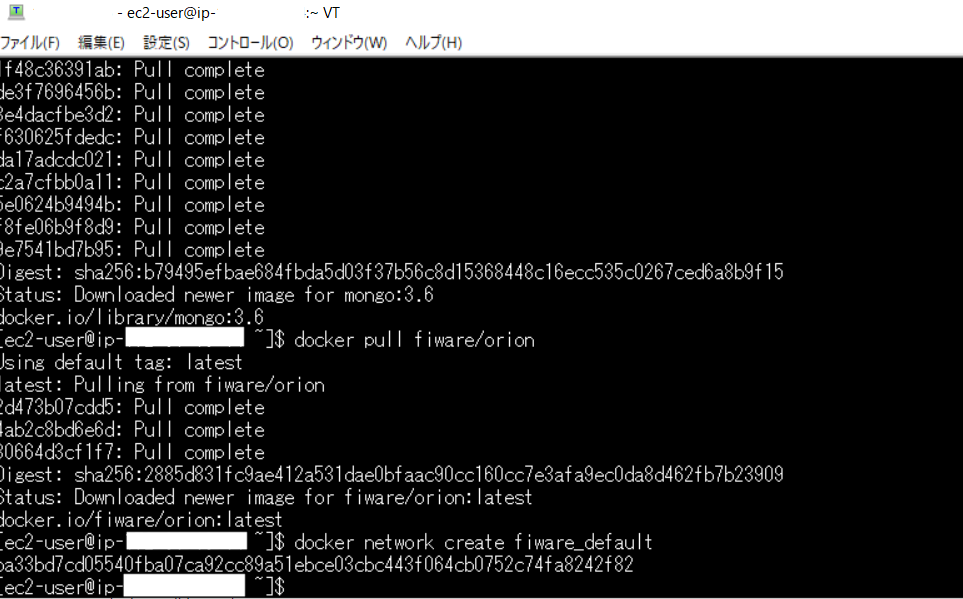
上記の様な画面が表示されるとFIWAREのインストールは完了です。
ここで終わっても良いのですが、それでは味気ないので実際にFIWAREを入れたdocker環境にローカル環境アクセスし、FIWAREのバージョンを確認してみましょう!
MongoDB データベースを実行している Docker コンテナを起動し、ネットワークに接続するには、次のコマンドを実行します 。
docker run -d --name=mongo-db --network=fiware_default \
--expose=27017 mongo:4.2 --bind_ip_all
Orion Context Brokerは、次のコマンドを使用して起動し、ネットワークに接続できま す。
docker run -d --name fiware-orion --network=fiware_default \
-p 1026:1026 fiware/orion -dbhost mongo-db
ここまでできればあとは、EC2のIPアドレスに/version/をつけてアクセスしてみてください!FIWAREのバージョンを見ることができます。
ex. http://124.654.493:1026/version/
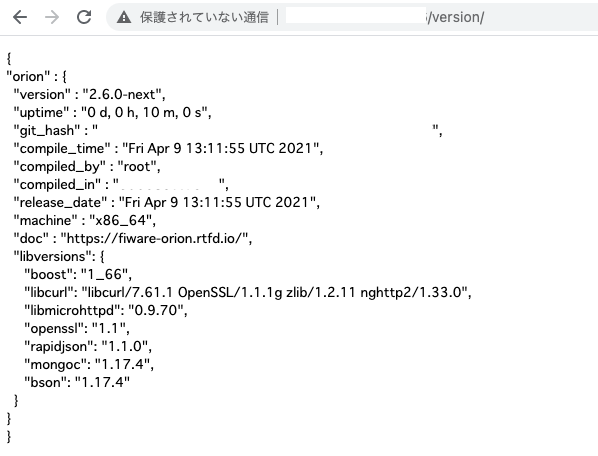
できた!!!
今日の内容は以上です!少しでも参考になれば幸いです。
それではまた後日!
参考サイト
【Androidアプリケーションの限定配信を実現】Firebase App Distribution

朝起きてブログ、仕事が終わってから筋トレした後にもブログを書いているゆきとです。
本日は、Androidアプリケーションのテスター向け配信手段の一つである「Firebase App Distribution」の使い方について紹介します。
はじめに
※Firebase App Distribution はベータ版リリースです。
これは、機能が後方互換性のない方法で変更される可能性があることを意味します。
ベータ版リリースは、SLA または非推奨ポリシーの対象ではなく、サポートが限定的であるか、またはサポートがまったく提供されない場合があります。
何ができるのか
登録したテスターに対してアプリ配信を行えます。
配信の手順
- アプリをFirebaseコンソールに登録する
- テスターを事前登録
- apkファイルをコンソールに追加
- 配信登録で配信先を選択し配信
- 端末側でFirebaseAppTransfer設定
- FirebaseAppTransferから配信されたテスター用アプリをインストール
1. アプリをFirebaseコンソールに登録する

今回はテスト用に新しく作成したプロジェクト「NewAgent」に追加します。
左側コンテンツツリーから「App Distribution」を選択します。
2.テスターを事前登録

この画面の上部タブ切り替えで「テスターグループ」を選択します。

テスターになるアカウントのメールアドレスを追加します。
一括追加も可能です。
3. apkファイルをコンソールに追加
上部ドラッグエリアにapkファイルをドラッグしてアップロードします。
4.配信登録で配信先を選択し配信
ここでは先ほど追加したテスターを選択し「次へ」をクリックします。
リリースノートが必要であれば追加し「一人のテスターに配布」で配信を実行します。
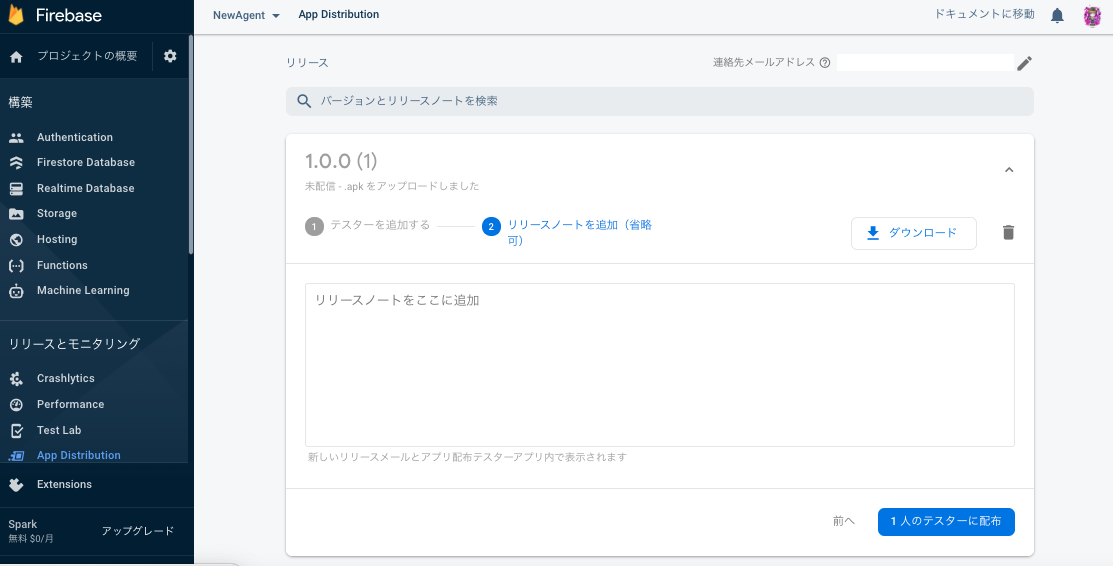
5.端末側でFirebaseAppTransfer設定
未経験で招待される端末では招待メールが届きます。
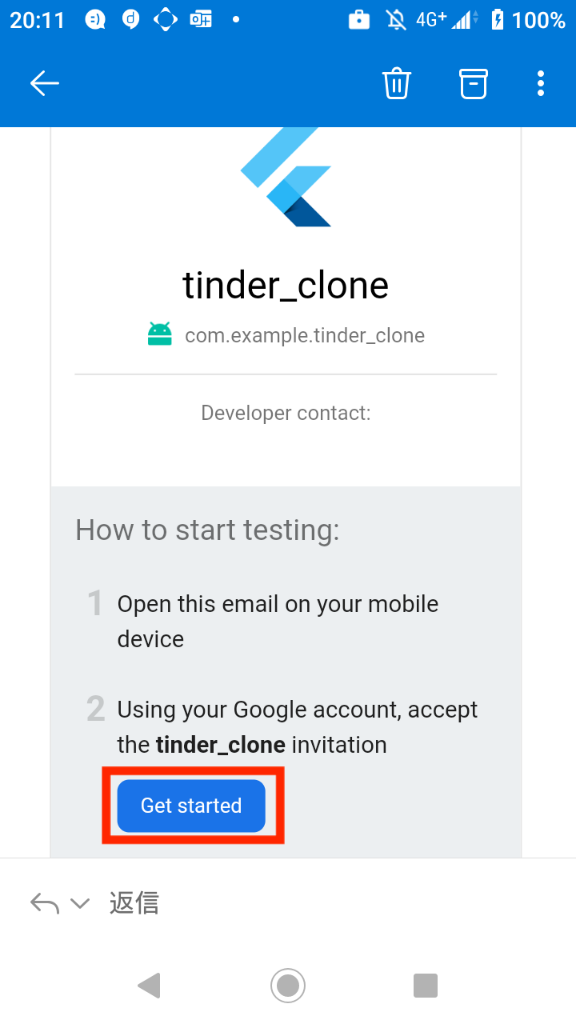
招待メール内の「Get started」でFirebase App Transferアプリがセットアップされます。

※この際Chromeからアプリインストール許可を要求される場合は許可しておきます。
※Googleのアカウントにログインしていない場合、Googleアカウントへのログインを要求されます。
6. FirebaseAppTransferから配信されたテスター用アプリをインストール
招待に応じた後、アプリのダウンロードを行います。(ここからは一連の流れとなるので、写真を追いながらアプリを端末にインストールしてください。)
写真の見方 : 「左 => 右 => 左下 => 右下」の順で確認していきます。
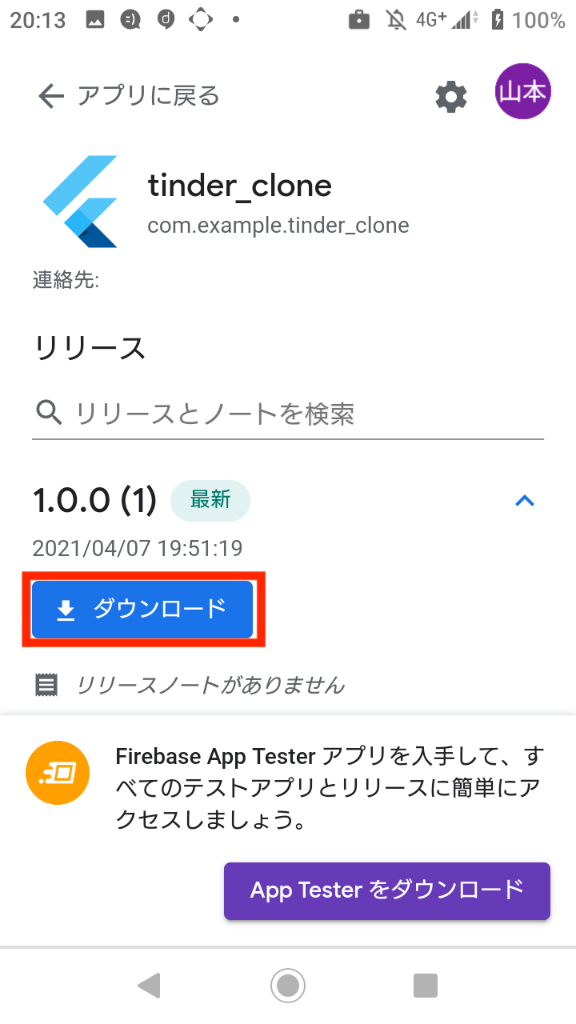

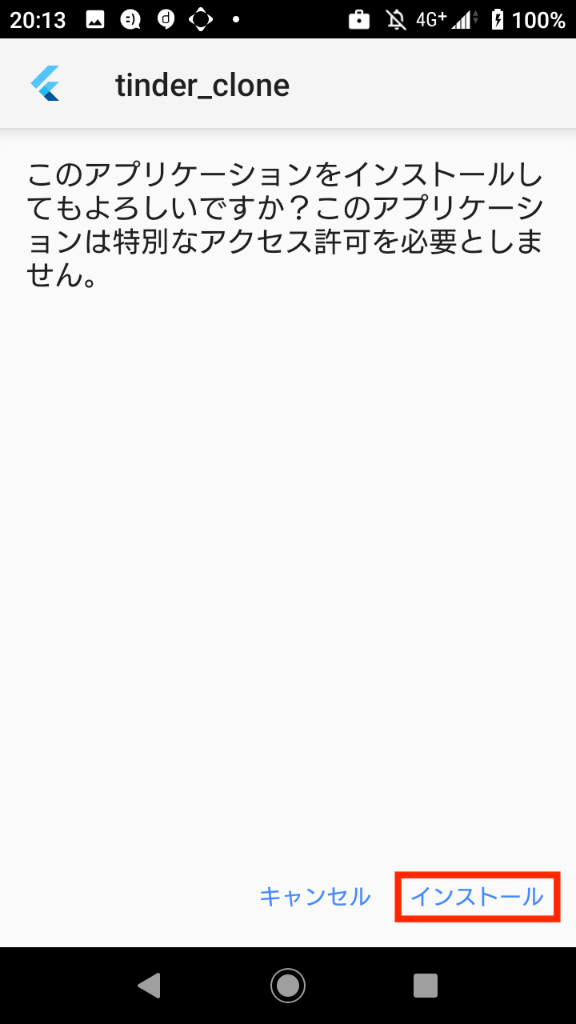
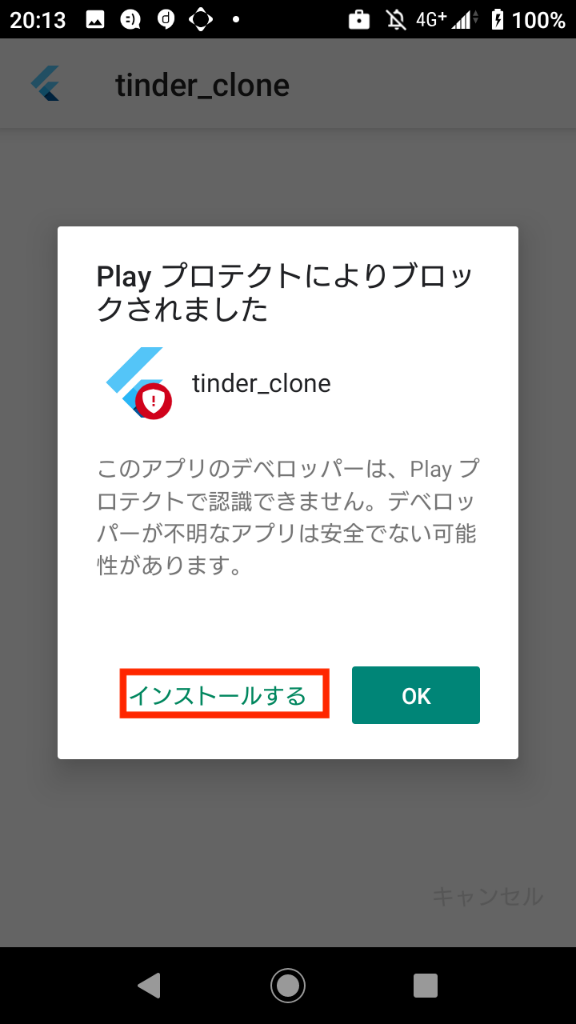
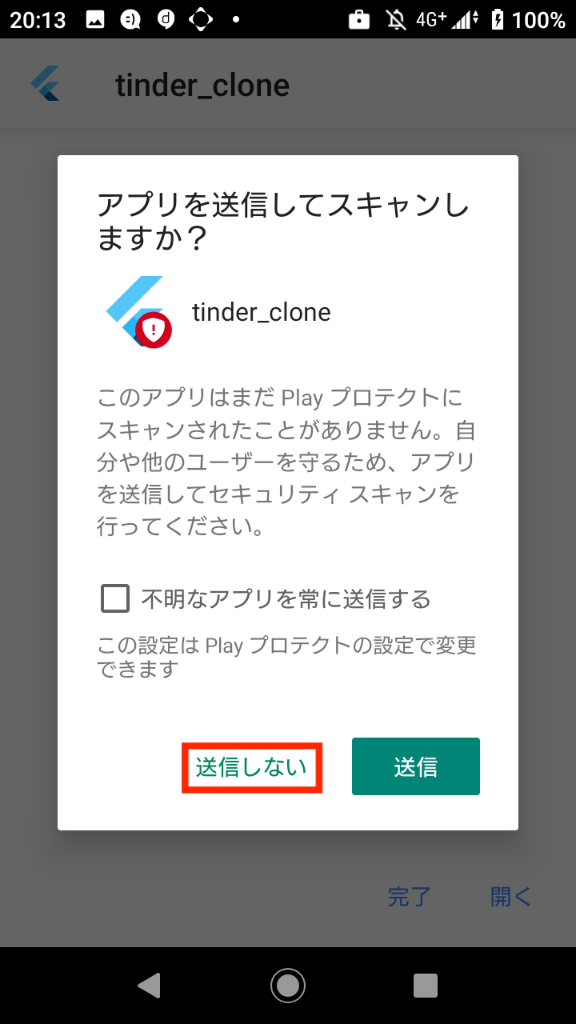
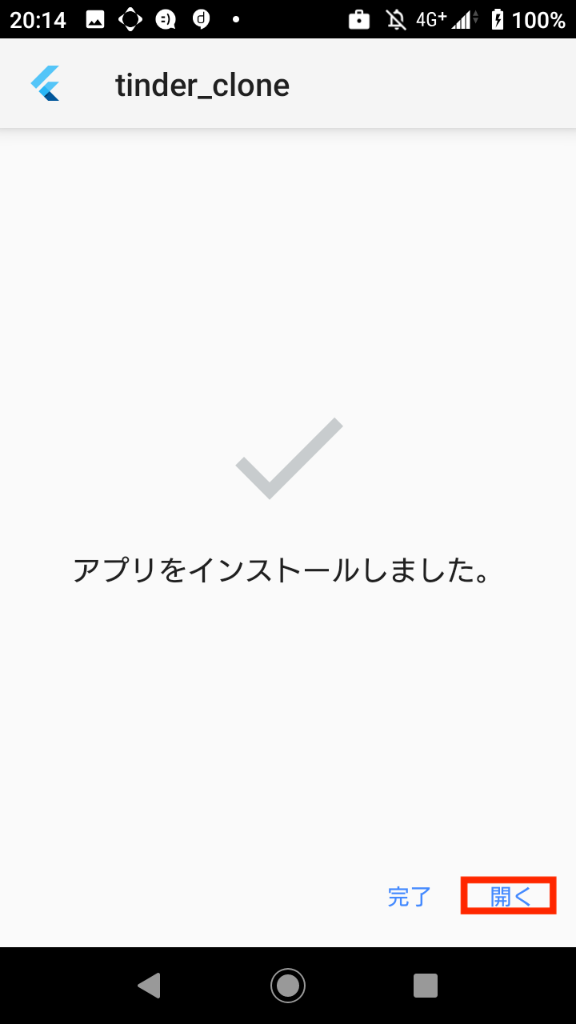
ここまでくれば、アプリのインストールは完了です。

基本的には表示されているボタンを押し続けるだけでよいです。
※この際Firebase App Transferからアプリインストール許可を要求される場合は許可しておきます。
注意点
- Firebase App Transferを設定するに当たって、Googleアカウントが必要となるので、事前に作成しておきます。(テスター用gmailアドレスもこの段階で作成したアカウントのgmailにするとOKです)
- 端末側では「不明なアプリケーションのインストールを許可」しておく必要があります
後書き
今日の内容は以上です!!
これで明日からAndroidアプリを限定公開できますね!🤗
楽しいAndroidライフを!それではまた後日ー
【わかるEC2】Microsoft Windows Server 2019でDocker環境を作ろう!

最近、大きな仕事が一つ終わったせいか、燃え尽き症候群になりかけているゆきとです。なんとかブログを書いたりプログラムを書いたりして燃え尽きないように日々行動を続けて自分を騙しています笑
本日はAWS EC2でWindows環境を作り、そのWindows環境にDocker環境を入れる方法を紹介したいと思います。
EC2インスタンス設定内容
下記の4点以外はデフォルトの設定のまま利用可能
- リージョン : 東京リージョン(ap-northeast-1)
- AMI : Microsoft Windows Server 2019 Base
- インスタンスタイプ : t2.large (t2.microでもいける?)
- セキュリティグループ: 3389番ポートのみを開放していればよい
* 東京リージョン選定理由 : 海外にデータセンターを起きたくないため
* インスタンスタイプt2.large選定理由 :
EC2上に仮想環境を作るときに2 vcpu 数、8 GB メモリ程度のスペックが必要になるため( https://teratail.com/questions/159118 ) => 私は先にこちらの記事を見ていたので、最初からt2.largeにしてしまいましたが、みなさんが設定される時は、t2.microで試してみてください。
EC2でDocker in WindowsOS環境作成する
それでは作成していきます。手順はふたつです。
一つずつ説明していきます。
1. AWS EC2インスタンスをWindows環境で作成
EC2インスタンス設定内容で記述した条件で、EC2を作成する。(ここはそんなに難しくないので割愛します)
*EC2インスタンスを設定するときに作成したEC2へのアクセスキーは控えておいてください。(.pem形式のファイルです)手順2で使用します。
手順2を詳しく解説します。
2. 作成したEC2インスタンスにRDP接続を行い、Docker環境を構築する
まず、EC2インスタンスへRDPする前準備として、EC2インスタンスへRDP ( RemoteDesktopProtocol ) 接続(インスタンスを選択 > ヘッダー付近にある接続)を行クリックします。
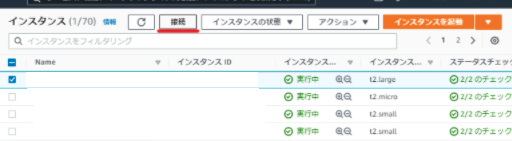
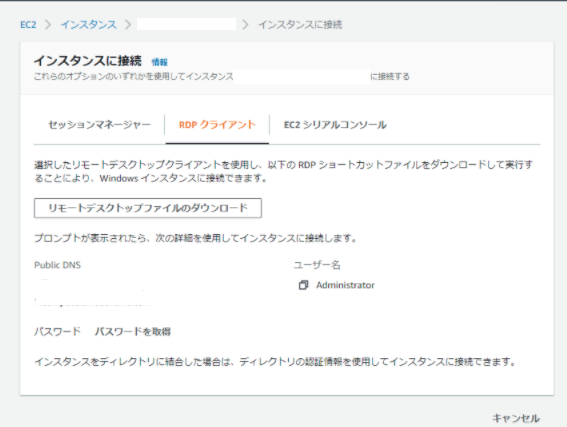
こちらの画面まで遷移した後、下記2点を行います。
①リモートデスクトップファイルのダウンロード
②パスワードの発行(EC2へのアクセスキーを使って、パスワードを発行します。このパスワードは、リモートデスクトップのログイン時に利用します)
ここまで行えば、EC2インスタンスへRDPする前準備は完了です。
次に、EC2へのRDP接続を行っていきます。
やり方はシンプルで、先程①リモートデスクトップファイルのダウンロードでダウンロードした.rdpファイルをダブルクリックして実行。
その後、何度か許可を求められたりする画面に全て許可をいれ、パスワード入力画面に移行。
そのパスワード入力画面で、先程②パスワード発行で作成したパスワードを入力して、接続すれば無事EC2にアクセスできます。

ここまでくれば、あと一息です。コマンドをぽちぽちしてDockerをインストールしていきましょう。(2021/04/06現在はこのコマンドで実行できますが、一年後同じ様にできるとは限りません)
Qiitaの記事(https://qiita.com/Targityen/items/c4ed5ed9b9227e2f573d )を参考にしつつ、設定を進めていきます。(記事の内容が古いので、適宜コマンドに変更を加えています)
1. RDP接続したEC2内で、PowerShellを起動
(右クリック => Personalize => powershellで検索 => PowerShell Developer Settings => PowerShell => Show settings)
2. Hyper-Vをインストール
コマンド2Install-WindowsFeature RSAT-Hyper-V-Tools -IncludeAllSubFeature
3. コンテナ機能をインストール
コマンドPowerShell Install-WindowsFeature containers
4. ここまで設定できれば一度、再起動を行う
コマンドRestart-Computer
* EC2への接続が削除されるはずなので、再度RDP接続を行っておく
5. DockerEEをインストールするためのプロバイダをインストール
コマンドPowerShell Install-Module -Name DockerMsftProvider -Repository PSGallery -Force
6. DockerEEのインストール
コマンドPowerShell Install-Package -Name Docker -ProviderName DockerMsftProvider -Force
7. ここまで設定できれば一度、再起動を行う
コマンドRestart-Computer
*ここでもEC2への接続が削除されるはずなので、再度RDP接続を行っておく
以上でDockerのインストールは完了です。7. で再接続したEC2でDockerがインストールされているかをdocker --versionコマンドで確認して、無事確認できればdockerがインストールは完了です。
*もし今までの流れの中でうまくいかない部分があれば、エラー文を一つ一つgoogle先生で調べてみてください。(エラー文でググるとたいていなんとかなります)
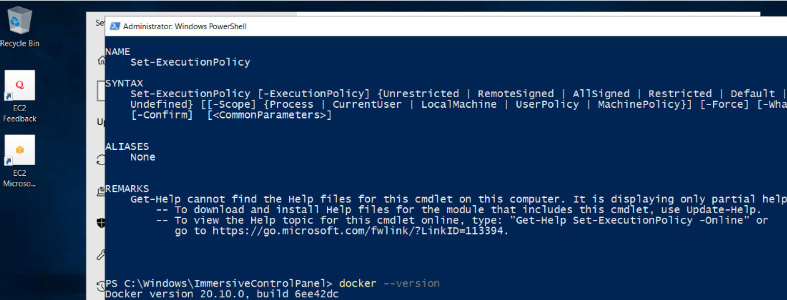
以上、今日もブログを読んでくださり、本当にありがとうございます。
それではまた後日!
【わかる】EC2のCronの設定方法

お久しぶりです。(久しぶりすぎて忘れられていると思いますが)半年ぶりのゆきとです。
ここ半年ほど開発案件に付きっきりになっており、長らくブログを書いておりませんでした。ですので、今、こうやってブログをかける幸せを噛み締めているところです笑
さて余談もそこそこに本題にはいっていきます。
今日はEC2でのCron設定方法を紹介します。
すでにたくさんの記事で書かれている内容かと思いますが、他の記事をみていると痒い所に手が届いていないような記述がされているケースが多く、一つの記事をみただけではCronの設定がうまくできませんでした(いろんな記事の情報を寄せ集めてなんとか設定できました)。
なのでこの記事では、こうしたらEC2でCronの設定ができる(2021/04/04現在)という方法をこの記事だけで完結する様に紹介します。
*いくつか、つまずくポイントが隠されているので、そこは太字で示します。
1. EC2にSSHでログイン
まずEC2にSSHでログインします。(ここは特に問題はないと思うのでさらっとだけ紹介します)
EC2 SSHログインssh -i ~/.ssh/公開鍵名.pem ユーザ名@IPアドレス
ex. ) ssh -i ~/.ssh/test-test.pem ec2-user@18.111.191.119
ex. ) ssh -i ~/.ssh/test-test.pem ec2-user@18.111.191.119
EC2にログインができたら、次はCronの設定です
2. EC2内のCrontabの編集
EC2内のCrontab設定ファイル(/var/spool/cron/root)を編集します。
EC2 Crontab編集sudo crontab -e
//1〜3行はcronを適切に動作させるためのおまじない(cronのパスを設定しています。ここを設定しないと動かないのですが、他の記事では書かれていない場合が多々ありました)
//4行目はすでにEC2で設定されているcron
//5行目は今回追加したcron (毎分 "Is this working" と出力される)
上記の様にCrontabが設定できれば、次に動作確認を行います。
3. Cronの動作確認
EC2内のCron動作を下記のコマンドから確認します。
Cron動作確認sudo tail -f /var/log/cron

図の様に1分ごとにecho "Is this working"コマンドが実行されているのが確認できると思います。
ここまでできればEC2でのCron設定は終了です。あとは、自分がcronをしたいファイルごとにcronを設定するだけとなります。
うまく設定できましたか?何かあれば、右上のtwitterからDMください!この記事が少しでも参考になれば幸いです。
それではまた後日!!

【コピペでできるpython】twitter apiを使ってフォロワーのtwitter idを取得してみよう!

万物は流転する。令和のヘラクレイトスことゆきとです。
今日はtwitter apiを使ってフォロワーのtwitter idを取得していきます。
*前回の記事の続きです。まだみてない方は前回の記事をみてください!と言いたいところではありますが、今回の記事だけをみても理解できるように書いていますので、前回の記事はみなくても大丈夫です笑
貼るだけ貼っておきます。
twitterから情報を取得する方法は2パターン (Beartokenを使うパターン, access tokenを使うパターン)があるのですが、後にいいねやリツートなどもしたいので今回はaccess tokenを使う方法でAPIを使用し、twitterから情報を取得します。
*twitterから情報の取得だけをしたい場合、Beartokenを使うパターンでもOKです。
詳しい2つの違いなどは下記のドキュメントを参照してください(英語なのは許してください...)
OAuth with the Twitter API | Docs | Twitter Developer
それでは作っていきましょう!
前提条件
もしまだtwitterのAPIキーを取得されてない方はこちらのサイトを参考にAPIキーを取得してください。(めちゃくちゃわかりやすくまとめてくれてます)
開発環境
実行結果

このような形でフォロワーのtwitter idを取得できます!
今回のソースコードではフォロワーが7万5千人以下の方であれば、一度でフォロワー全てのtwitter idを取得できます。
ソースコード
pprintとjsonは最初から入っていますが、requests_oauthlibはライブラリをインストールする必要があるので、インストールしてください。
ライブラリのインストールpip install requests_oauthlib
以下のソースコードはコピペでOKです!!(一部変えるところがあるので、ちゃんと最後まで読んでくださいね!)
ファイル名 : twitter_get_follower_twitter_id.py
このコードのAPIキーの部分(OAuth1..)を自分が取得したものに変えていただいて、コードを実行してください。
これで実行ができるはずなので、最初に示した実行結果と同じ結果になるかを確認してください。
無事表示されれば終了です!お疲れ様でした!
どうでしたか?少しでも参考になれば幸いです。
それではまた後日!!
参考
自分のtwitter id・名前・フォロワー数の取得 : GET users/show | Docs | Twitter Developer
フォロワーtwitter idの取得 : GET followers/ids | Docs | Twitter Developer
【コピペでできるpython】twitter apiを使ってフォロワー数を取得してみよう!

こんにちわ。ゆきとです。
最近、自分よりも若い人が自分よりも圧倒的に結果を出しているのをみて、打ちのめされています。自分は自分、他人は他人と割り切り努力を続けます。
余談はこのくらいにして、今日はtwitter apiを使ってフォロワーを取得していきます。
twitterから情報を取得する方法は2パターン (Beartokenを使うパターン, access tokenを使うパターン)があるのですが、後にいいねやリツートなどもしたいので今回はaccess tokenを使う方法でAPIを使用し、twitterから情報を取得します。
*twitterから情報の取得だけをしたい場合、Beartokenを使うパターンでもOKです。
詳しい2つの違いなどは下記のドキュメントを参照してください(英語なのは許してください...)
OAuth with the Twitter API | Docs | Twitter Developer
それでは作っていきましょう!
前提条件
もしまだtwitterのAPIキーを取得されてない方はこちらのサイトを参考にAPIキーを取得してください。(めちゃくちゃわかりやすくまとめてくれてます)
開発環境
実行結果

このような形でフォロワー数を取得できます!
自分のtwitter idとかツイッター名とかも取得できるので、自分の欲しい情報を取得してみてください。
ソースコード
pprintとjsonは最初から入っていますが、requests_oauthlibはライブラリをインストールする必要があるので、インストールしてください。
ライブラリのインストールpip install requests_oauthlib
以下のソースコードはコピペでOKです!!(一部変えるところがあるので、ちゃんと最後まで読んでくださいね!)
ファイル名 : twitter_get_follower.py
このコードのAPIキーの部分(OAuth1..)を自分が取得したものに変えていただいて、コードを実行してください。
これで実行ができるはずなので、最初に示した実行結果と同じ結果になるかを確認してください。
無事表示されれば終了です!お疲れ様でした!
どうでしたか?少しでも参考になれば幸いです。
それではまた後日!!
【Python MySQLエラー】ImportError: No module named mysql.connector

こんにちわ。ゆきとです。
今日は少しハマったエラー「ImportError: No module named mysql.connector」の解決策を、仮想環境 (Anaconda) を使う場合に絞って紹介させていただきます。
ちなみに仮想環境を使わない環境の場合は、純粋にライブラリのインストールミスだったりするので、下記の記事を参考にしながらもう一度ライブラリのインストール(pip install mysql-connector-python)から行ってみてください。
【mysql-connector-python】PythonからMySQLを操作する - footmark
それではさっそく本題の仮想環境 (Anaconda) でのmysql.connector importエラーを解決していきます。
私の環境は下記の通りです。
解決策については、結論だけ書きます。
「Anacondaなどの仮想環境でmysqlを操作したい場合、その仮想環境自体にmysqlを操作するためのライブラリを入れる必要があります」(私はここを忘れて四苦八苦していました)
Anacondaでmysqlを操作したい場合は下記のコマンドを入力する。
その後、通常の環境でmysqlを操作するような形で実装をしていけます。
mysqlの操作はこちらの記事を参考に行ってください。
【mysql-connector-python】PythonからMySQLを操作する - footmark
たったこれだけのエラーに1時間ほど費やしてしまった。私もまだまだです。みなさま一緒に努力していきましょう!!!!
今日の内容は以上です。
それではまた!